简介
Knuth-Morris-Pratt字符串查找算法,简称为“KMP算法”,常用于在一个文本串S内查找一个模式串T的出现位置。这个算法由Donald Knuth、Vaughan Pratt、James H. Morris三人于1977年联合发表,故取这3人的姓氏命名此算法。时间复杂度O(|S|+|T|)。
朴素算法
给出一个最为常见的朴素字符串模式匹配算法,枚举文本串S的每一位,作为起点与模式串T进行匹配。时间复杂度O(|S|*|T|)。
1int simple(char* s, char* t, int n, int m)
2{
3 int i = 0, j = 0;
4 while (i < n)
5 {
6 if (s[i] == t[j]) {
7 i++, j++;
8 if (j >= m) { // 匹配成功
9 return i-j;
10 }
11 } else {
12 i = i-j + 1;
13 j = 0;
14 }
15 }
16 return -1;
17}
朴素算法的运行过程如下:
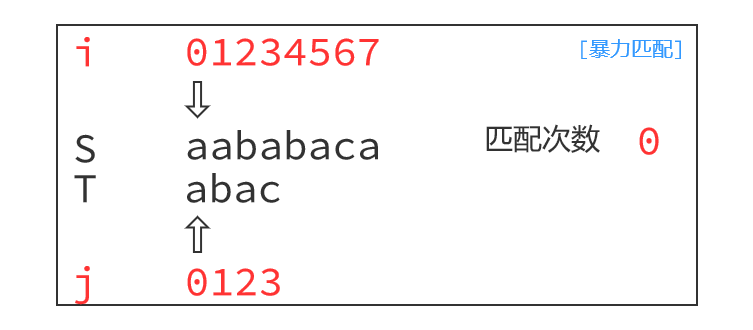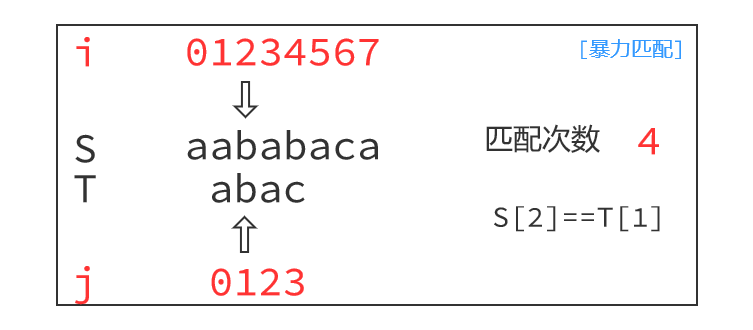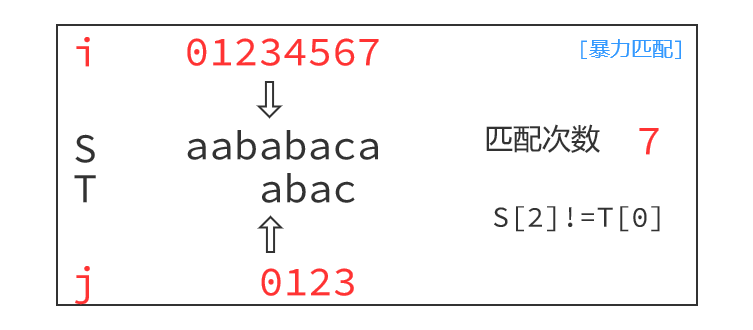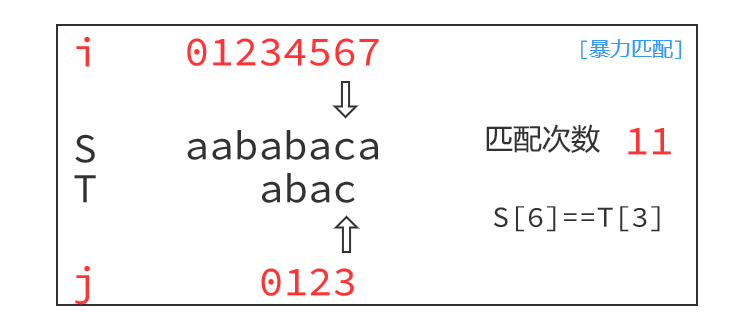
注意到,如下图,枚举以S[1]为起点,匹配到最后一个字符,S[4]!=T[3],失配之后朴素做法是指针回退,以S[2]为起点开始下一轮匹配,即i=i-j+1, j=0。
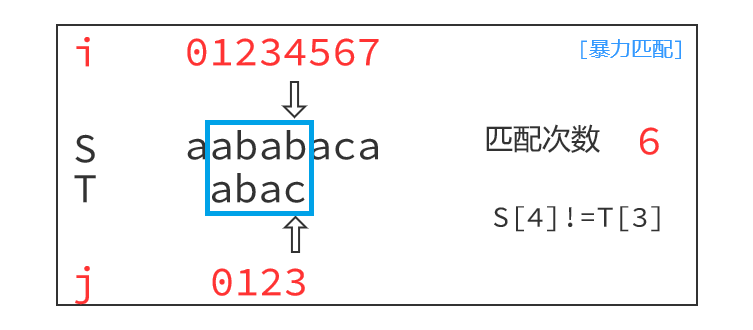
毫无疑问,随着文本串S的长度增加,每一次回退重新匹配会花费大量的时间。那么有没有办法优化呢?
next数组
通过分析模式串T可以得到next数组,也可以当作fail数组理解。对于模式串T="abac",当匹配到'c'时失配了,那么说明前面的"aba"已经匹配成功,"aba"**最长的相等前缀后缀(不包括本身)**是'a',那么失配'c'后,我们可以跳过s[3]='a'(文本串S"aba"的后缀)与T[0]='a'(模式串T"aba"的前缀),直接匹配S[4]='b'与T[0]='b'。
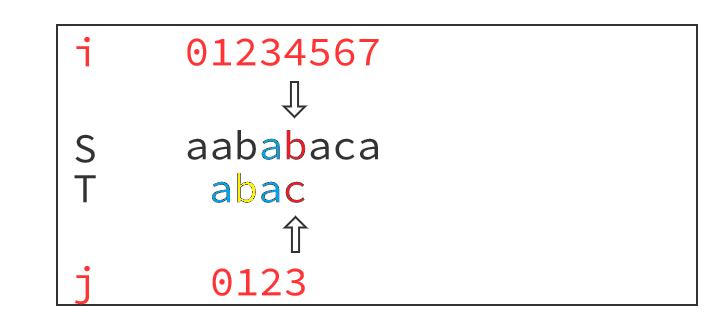
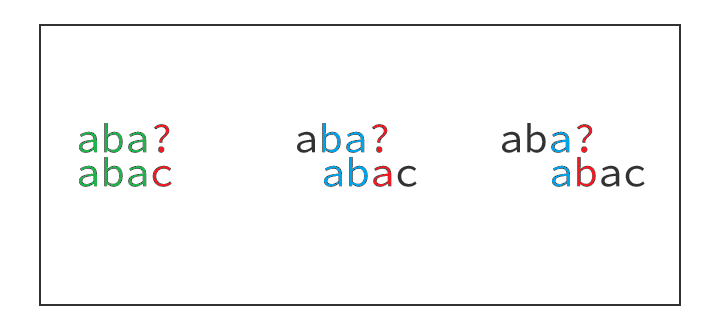
为什么是最长的、相等的、不包括本身的前缀后缀呢?看下图自行理解。
由下表可以看出最长相等前缀后缀整体右移,首位加上-1,即是next数组。
| 模式串 | a | b | a | c |
|---|---|---|---|---|
| 最长相等前缀后缀 | 0 | 0 | 1 | 0 |
| next数组 | -1 | 0 | 0 | 1 |
next数组优化
对于失配时S[4]='c'与T[3]='b'不相等,由T[1]='b'与T[3]='b'相等,得出T[1]='b'与S[4]='c'也不相等,我们可以跳过这一步匹配。
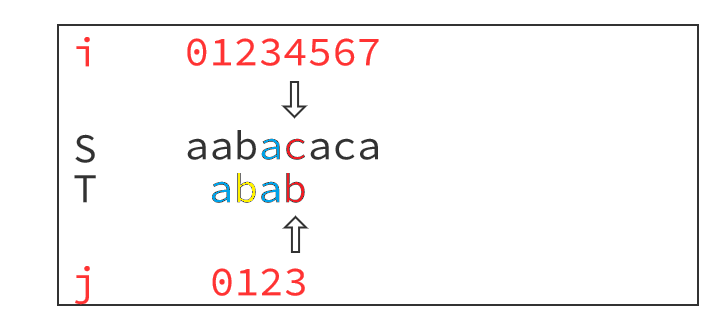
注意C++中next是关键字(迭代器的一个函数),以及字符串下标从0开始和从1开始的代码稍有不同,注意必须求到next[|T|],求字符串匹配数量以及最小循环节都需要用到。下面给出的是字符串下标从0开始的next数组的一种求法:
1int nxt[mxn];
2
3void getnxt(char* t, int m)
4{
5 int i = 0, j = -1; nxt[0] = -1;
6 while (i < m)
7 {
8 if (j == -1 || t[i] == t[j]) {
9 i++, j++;
10 // if (t[i] == t[j])
11 // nxt[i] = nxt[j]; // next数组优化
12 // else
13 nxt[i] = j;
14 } else
15 j = nxt[j];
16 }
17}
KMP算法
有了next数组,下面给出KMP算法代码,与朴素算法类似,但是i不用回退了,可以看出求next数组的过程也是一个模式串T与自身匹配的过程。
1int KMP(char* s, char* t, int n, int m)
2{
3 int i = 0, j = 0, ans = 0;
4 while (i < n)
5 {
6 if (j == -1 || s[i] == t[j]) {
7 i++, j++;
8 if (j >= m) { // 匹配成功
9 return i-j;
10 }
11 } else
12 j = nxt[j];
13 }
14 return -1;
15}
KMP算法的运行过程如下:
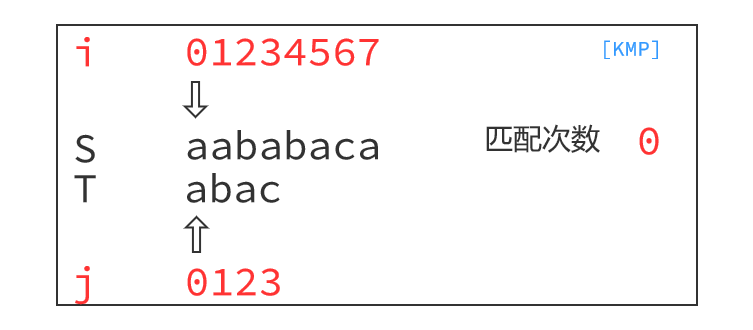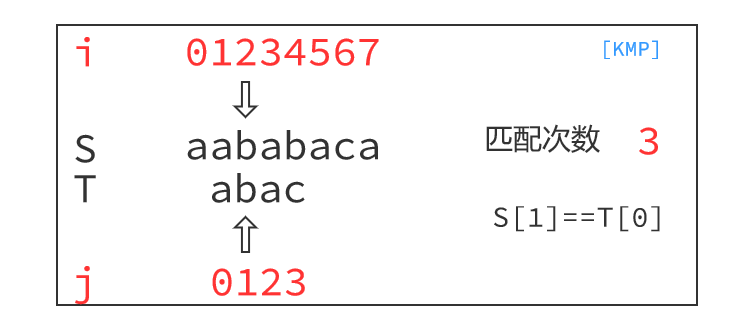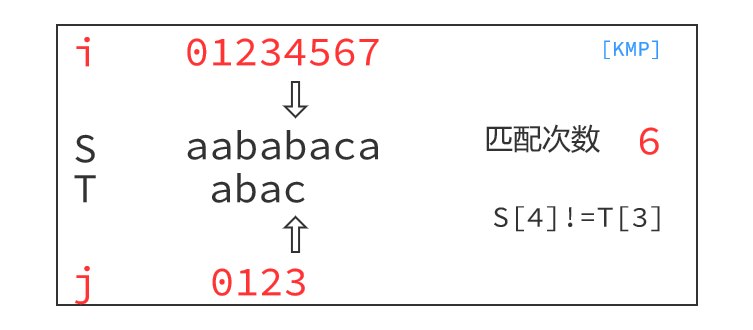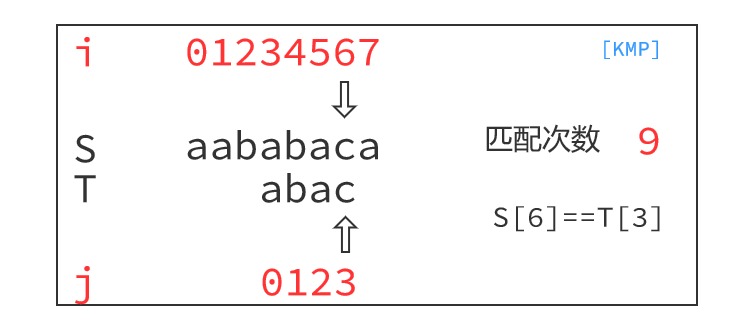
最小循环节
参考 KMP模板,最小循环节。
定理:
假设S的长度为len,则S存在最小循环节,循环节的长度L为len-next[len],子串为S[0…len-next[len]-1]。
(1)如果len可以被len-next[len]整除,则表明字符串S可以完全由循环节循环组成,循环周期T=len/L。
(2)如果不能,说明还需要再添加几个字母才能补全。需要补的个数是循环个数L-len%L=L-(len-L)%L=L-next[len]%L,L=len-next[len]。
| index | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 |
|---|---|---|---|---|---|---|---|---|
| char | a | b | c | d | a | b | c | |
| next | -1 | 0 | 0 | 0 | 0 | 1 | 2 | 3 |
为方便说明,先设字符串的长度为len,循环子串的长度为L
例1 s0s1s2s3s4s5,next[6]=3 即s0s1s2=s3s4s5 很明显可知:循环子串为s0s1s2,L=len-next[6]=3,且能被len整除。
例2 s0s1s2s3s4s5s6s7,next[8]=6 此时len-next[8]=2,即L=2 由s0s1s2s3s4s5=s2s3s4s5s6s7 可知s0s1=s2s3,s2s3=s4s5,s4s5=s6s7 显然s0s1为循环子串
例3 s0s1s2s3s4s5s6,next[7]=4 此时len-next[7]=3,即L=3 由s0s1s2s3=s3s4s5s6 可知s0s1=s3s4,s2s3=s5s6 从而可知s0s1s2=s3s4s5,s0=s3=s6 即如果再添加3-4%3=2个字母(s1s2),那么得到的字符串就可以由s0s1s2循环3次组成
对于一个字符串,如abcd abcd abcd,由长度为4的字符串abcd重复3次得到,那么必然有原字符串的前八位等于后八位。也就是说,对于某个下标从0开始的字符串S,长度为len,由长度为L的字符串s重复R次得到,当R≥2时必然有S[0…len-L-1]=S[L…len-1]。
那么对于KMP算法来说,就有next[len]=len-L。此时L肯定已经是最小的了(因为next的值是前缀和后缀相等的最大长度,即len-L是最大的,那么在len已经确定的情况下,L是最小的)
模板
1char s[mxn], t[mxn];
2int nxt[mxn];
3
4void getnxt(char* t, int m)
5{
6 int i = 0, j = -1; nxt[0] = -1;
7 while (i < m)
8 {
9 if (j == -1 || t[i] == t[j]) {
10 i++, j++;
11 // if (t[i] == t[j])
12 // nxt[i] = nxt[j]; // next数组优化
13 // else
14 nxt[i] = j;
15 } else
16 j = nxt[j];
17 }
18}
19
20int KMP(char* s, char* t, int n, int m)
21{
22 int i = 0, j = 0, ans = 0;
23 while (i < n)
24 {
25 if (j == -1 || s[i] == t[j]) {
26 i++, j++;
27 if (j >= m) {
28 // ans++;
29 // j = nxt[j];
30 return i-j;
31 }
32 } else
33 j = nxt[j];
34 }
35 // return ans;
36 return -1;
37}
38
39int main()
40{
41 scanf("%s %s", s, t);
42 getnxt(t, strlen(t));
43 for(int i=0; i<strlen(t); i++){
44 printf("%d ", nxt[i]);
45 }
46 printf("\n");
47 printf("%d\n", simple(s, t, strlen(s), strlen(t)));
48 printf("%d\n", KMP(s, t, strlen(s), strlen(t)));
49 return 0;
50}